Error 403
A veces cuando intentamos entrar en una página web, obtenemos un mensaje de error cuyo código es 403. El mensaje que aparece varía pero puede ser uno de estos:
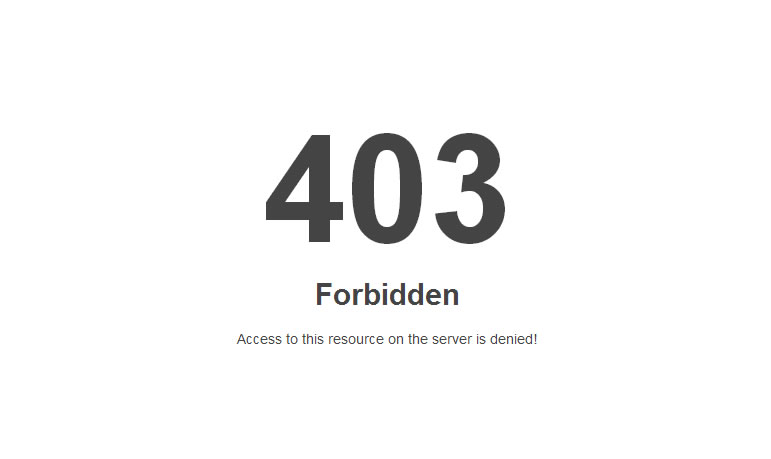
Forbidden: You don’t have permission to access [directory] on this server
HTTP Error 403 – Forbidden
Error 403 – Forbidden
403 forbidden request forbidden by administrative rules
403 Forbidden
Access Denied – You don’t have permission to access
Error 403
HTTP 403
Forbidden
El error 403 Prohibido es un código de estado HTTP que se produce cuando el servidor web entiende la solicitud pero no puede proporcionarte acceso a una página web.
Las causas pueden ser muy variadas y las soluciones son laboriosas y complejas. Existen infinidad de artículos en internet donde se explica detalladamente las formas de evitar el error. A veces lo único que queremos es acceder a la página web y ya está. Bien, pues esto es lo que vamos a explicar aquí. Cómo se instala y utiliza un script que hace justamente eso que queremos sin mas.
Bypass-403
Arrancamos y actualizamos nuestra máquina Parrot Security.
Clonamos el script de github
git clone https://github.com/iamj0ker/bypass-403
A continuación damos permisos de ejecución:
cd bypass-403
chmod +x bypass-403.sh
Ejecutamos lo siguiente para que salga el banner de la utilidad:
sudo apt install figlet
Si no lo tenemos instalado, ejecutamos lo siguiente:
sudo apt install jq
jq es una herramienta de terminal multiplafatorma presente en Linux, macOS y Windows. La herramienta permite filtrar, extraer, buscar o modificar los datos dentro de un fichero JSON. Algunos usos específicos que podemos dar a jq son: Extraer y/o consultar elementos específicos almacenados en un fichero JSON.
Comando cURL
Como viene siendo ya una constante en las webs relacionadas con la ciberseguridad y el hacking, el nivel explicativo es nulo. Y en esta utilidad yo creo que se baten récords. Simplemente se publicita el título, una escueta instrucción para instalarla (porque es imprescindible, supongo) y punto.
Entonces, para entender qué hace y poder explicarlo, hay que analizar la propia utilidad que está escrita en la propia shell de Linux. Como es muy corta la pongo por aquí, aunque tb la podéis ver en el github:
Es decir, como podéis ver no es mas que un archivo de ejecución por lotes que todos conocemos de MS-DOS pero para Linux. En Linux, el lenguaje de scripting para ejecutar lotes de comandos Linux se llama bash. En este archivo de comandos , encontramos una sucesión de instrucciones curl.
Tenéis que saber que el comando curl existe para Windows, Linux y Mac.
Curl es una herramienta con interface de línea de comandos (CLI) que permite transferir datos entre un servidor web y nuestro equipo a través de una serie de protocolos que soporta la herramienta. Es pues una herramienta de protocolos. Entre los mas usados con curl tenemos HTTP pero soporta muchos mas protocolos.
¿Cómo funciona bypass-403?. Si os fijáis en el script, el comando admite 2 parámetros que son:
Toma esos dos parámetros, los concatena, lo cual forma una url y con esta url ejecuta un total de 24 comandos curl. Son como pruebas o sondeos de si una url devuelve un código extraño como por ejemplo el dichoso 403, pero también 404 (not found) y otros.
Es decir, no es que sea un bypass, porque no nos permite saltarnos esa página que da código de error 403, podéis hacer la prueba. Pero de alguna forma, esta combinación de comandos curl que contiene script se chivan de los sitios donde podemos tener url’s en nuestro sitio web, con lo cual es una buena herramienta para descubrir errores o posibles puntos débiles.

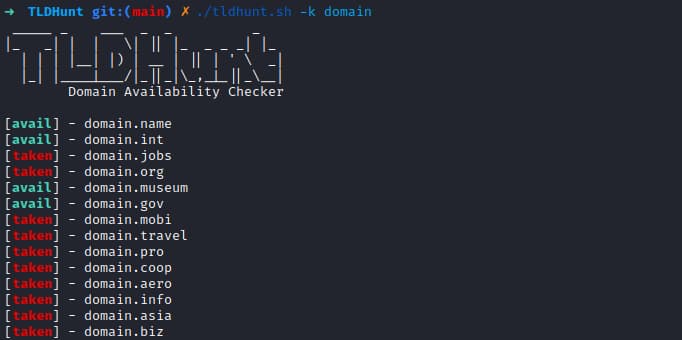
Como podemos observar, lo he ejecutado sobre la web de pruebas de mutullidae:
./bypass-403.sh http://128.198.49.198:8102
Y el resultado es el que está en pantalla. Como podemos ver hay multitud de url que dan error 403.
Al tratarse de un comando que va contra protocolos, como el HTTP o el HTTPS, hay que tener un buen conocimiento de los comandos internos y códigos internos o de error de dichos protocolos. El mismo 403 es un código de error del protocolo HTTP.
Si lo decimos de otra forma, el comando curl nos permite hacer manualmente, todas las peticiones internas que hace un navegador web. De hecho, los navegadores web, tienen la posibilidad de traducir cualquier cosa que le metemos en la barra de direcciones a comando curl.
Los protocolos soportados por curl son:
HTTP y HTTPS
FTP y FTPS
IMAP e IMAPS
POP3 y POP3S
SMB y SMBS
SFTP
SCP
TELNET
GOPHER
LDAP y LDAPS
SMTP y SMTPS
Conclusión
En fin, para terminar simplemente deciros, que el comando curl es mucho mas importante, extenso y complejo de lo que que aquí se ha expuesto. Permite hacer scripting de cualquier tarea que se haga con un navegador, y dado que hoy con un navegador lo hacemos TODO, pues ya os dais cuenta de lo importante que es. De hecho hay «ordenadores» que solo son el navegador. los «chrome pc». Además fijaros en la extensa lista de protocolos soportados.
Por poner solo un mínimo ejemplo de lo que se podría hacer, se podrían hacer conversiones de word a PDF de forma masiva en línea vía API. Pero esto ya lo veremos en otro post.